計算機教研部“人工智能”工作坊首播
——網絡爬蟲技術與相關的法律問題
3月27日下午,計算機教研部主辦的“人工智能”工作坊線上首播,第一次研討主題是網絡爬蟲技術與相關的法律問題。作為特約嘉賓,中國社會科學院大學副校長林維教授致開場辭,之后由徐衛克老師做技術講解,最后,林維教授與劉曉春博士做了主題發言。
計算機教研部主辦的“人工智能”工作坊計劃涉及時下主流的人工智能技術,共包括八個主題,分別是網絡爬蟲、區塊鏈技術、機器學習、文本分析、人工智能與圍棋、基于深度學習的圖像識別和情感識別、圖像和視頻分割以及目標檢測。每個主題由計算機教研部教師主講或邀校內外學術界或產業界專家共同主講,時間安排在本學期第四周開始的每周五下午。
林維副校長在開場致辭中表示,計算機教研部“人工智能”工作坊的舉辦,契合學校正在大力推動的新文科建設。中國社會科學院大學是人文社會科學方向的,希望努力實現傳統人文社會科學的創新和發展,師生一起進行探討,做一些學科建設的探索,希望以工作坊的形式,將人工智能、大數據等新興技術能與其他社會科學(如法學、經濟學等)結合,讓研究方法、研究范式、研究維度都有一個發展。特別感謝計算機教研部為我們其他學科的新文科建設開了一個特別好的頭。在技術革新變化之下,很多理念、很多學科都會遭遇挑戰。網絡爬蟲本是中性、中立的技術,利用技術操控干預現實社會在刑法中如何權衡已經是一個課題。我們傳統的媒介、傳統的文學、哲學觀念要隨著技術(如科技哲學)都要有所變化,后續要加以觀察、了解和學習。希望“人工智能”工作坊跟其他學院交流在一個平臺上面,嫁接不同的專業,實現學科融合,碰撞出火花。林維教授特別勉勵碩士、博士研究生同學開始著手探索這些新的領域,讓研究工作更上層樓。
在網絡爬蟲技術研討環節中,徐衛克老師首先介紹了網絡爬蟲的技術背景。要使用爬蟲,需要具備一定的數據庫、網站網頁技術、Python編程技術基礎。徐老師首先介紹了爬蟲框架Scrapy,數據庫及管理工具MongoDB、Navicat Premium,Python開發和編輯工具Anaconda和Spyder等的功能和安裝配置方法。
徐老師演示了對某市場網站中的商品價格數據進行了爬取和處理的全過程。從創建Scrapy工程,到創建爬蟲,運行爬蟲,分析頁面,提取詳細數據,修改條目,定義、創建、提交數據項,優化調試代碼,連接到MongoDB數據庫進行管理都進行了編碼實現。在講解編碼的同時,對爬取數據中出現的技術問題一一進行了說明與解答,也將關鍵代碼同步到工作坊群。在技術演練之余,徐衛克老師也提醒參與者,使用爬蟲一定要合法合規。

講解Scrapy技術框架
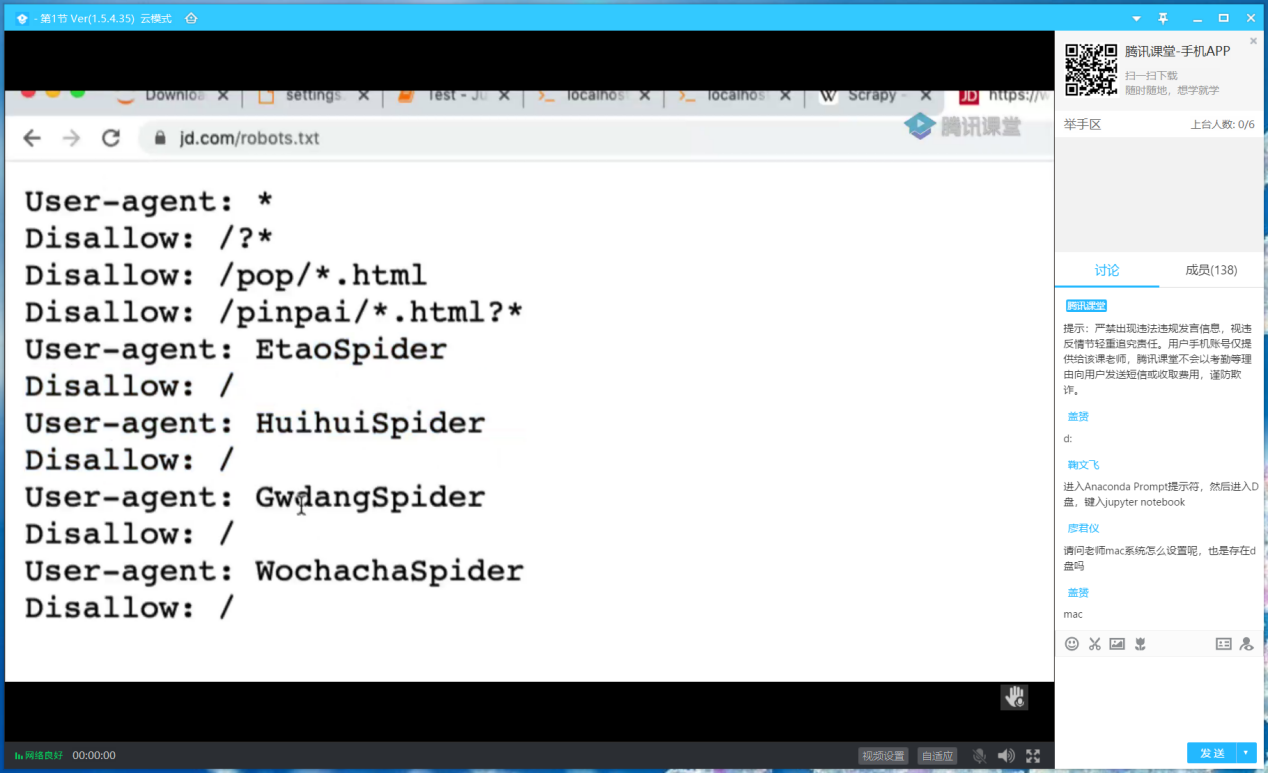
介紹Robots協議

編寫爬蟲
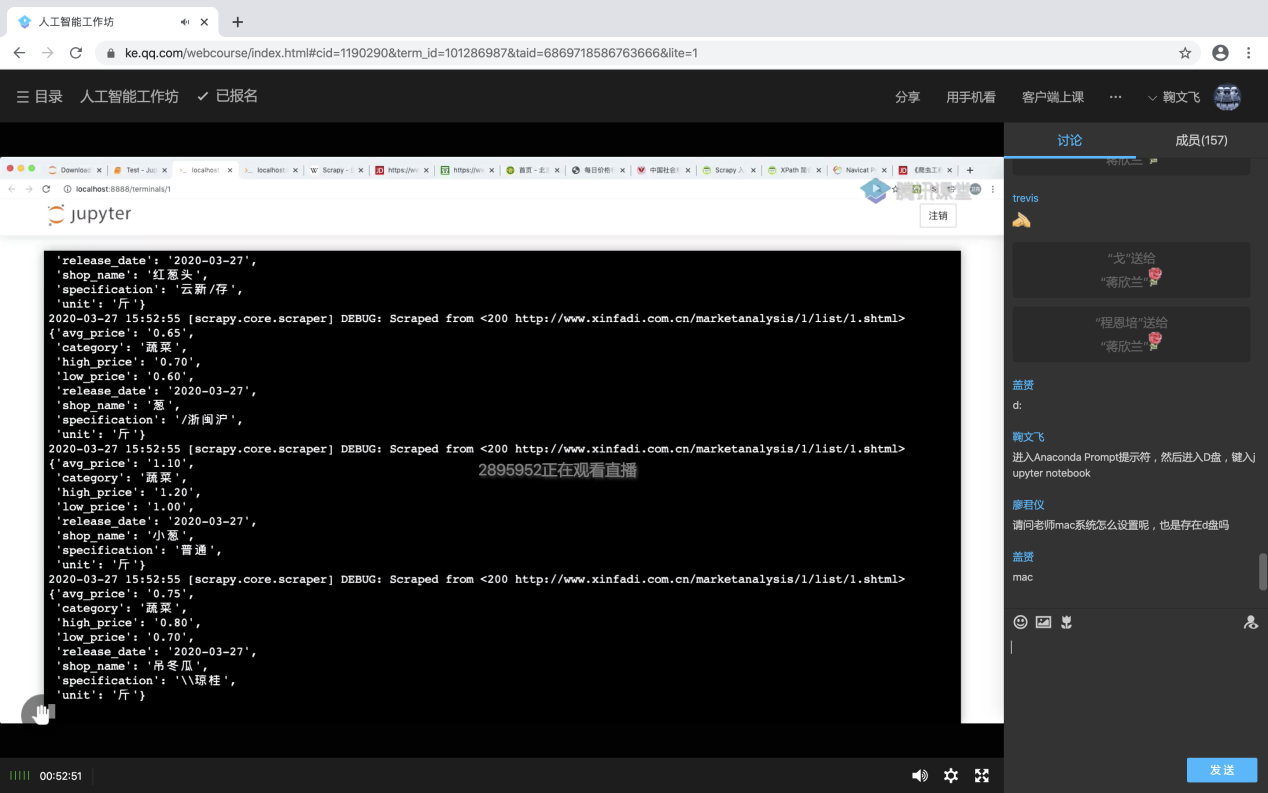
演示爬蟲工作過程
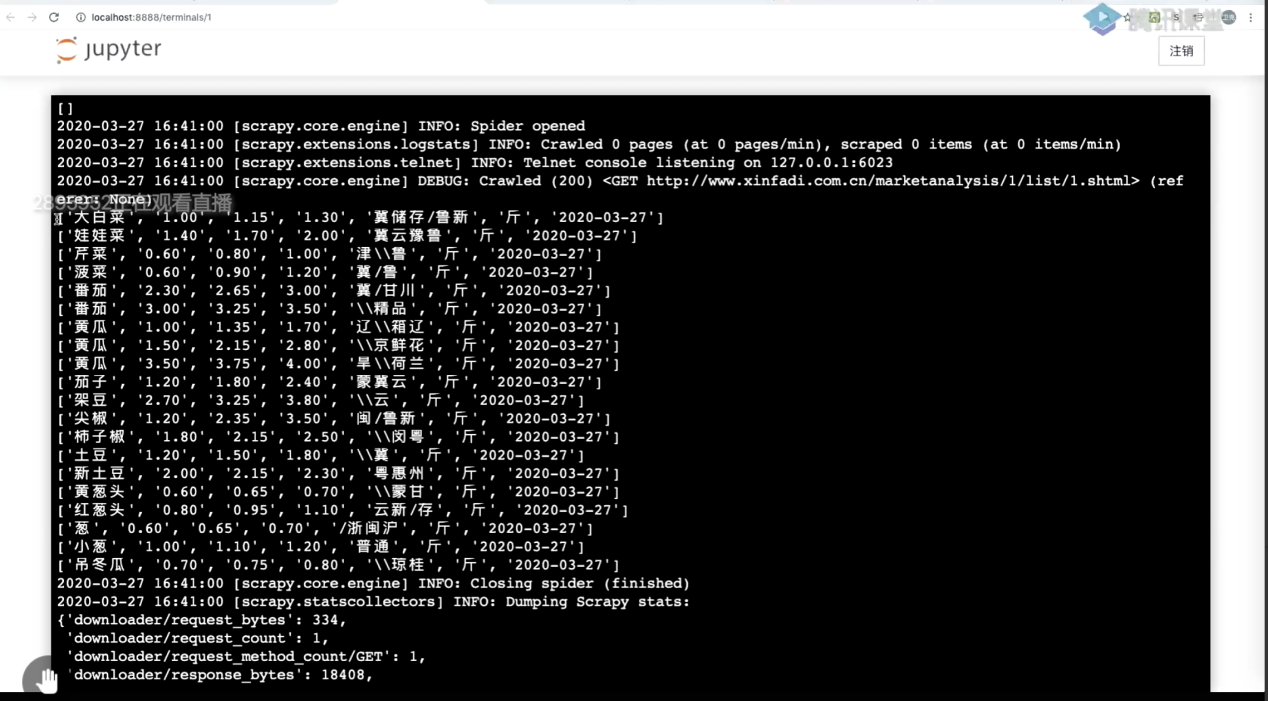
演示數據整理

爬蟲源碼優化
使用MongoDB數據庫管理數據
在邊講解邊實現的過程中,徐衛克老師已經進入“物我兩忘”的狀態,以至于有聽眾在工作坊中評論說:“感覺老師進入自己的世界了……”。計算機教研部全體老師也都在認真聆聽,同時在部門群中熱烈討論。時而關心技術實現細節,時而總結衛克經典語錄,時而思考如何落實直播細節,時而擔心那些“硬核”編碼是否會影響受眾接受度,同時關注工作坊活動對相關課程建設帶來的積極影響。

在工作坊群中與觀眾互動
接下來,中國社會科學院大學互聯網法治研究中心執行主任劉曉春博士就“數據爬取的競爭法規制”問題做了主題發言。發言主要針對數據爬取的法律相關問題進行了探討,諸如數據是否存在知識產權、商業秘密等合法權益,爬取行為是否屬于法律禁止的行為、是否違反協議或誠實信用原則、是否經過用戶授權等。
劉曉春博士列舉出近年來一些知名的數據爬取案例,探討了UGC案例,個人數據在通過OpenAPI授權下的權利歸屬案例,以及通過爬蟲技術獲取并無償使用的行為是否構成不正當競爭行為等。例如,robots協議已經進入到法律視野當中,如果網站放了robots協議,而爬蟲還是去抓數據,在法律上是什么責任?脈脈vs新浪微博案中,脈脈爬取微博數據,而有些數據是不公開的,這種情況可能構成對微博商業秘密的侵害。劉老師說,我們在法律上關心技術問題,一方面要把技術搞明白,另一方面要用法律來評價技術,搞清楚哪些可以做,哪些不可以做,搞清楚數據相關的利益如何去分配。

劉曉春博士主題發言
隨后,林維教授針對人工智能領域的法律問題進行了主題發言。林維教授說,在“人工智能”工作坊涉及的主題中,有很多技術都涉及到法律問題。目前人工智能問題討論的熱度極高,在法律界,有些法律工作者感覺有點虛火,可能過于超前或者科幻,目前還不能確定人工智能是否具有行為能力和承擔能力,另外一些業界學界人士則認為AI已經能成為法律的主體。這些都是值得探討的話題。林維教授舉出了人工智能應用方面的一個實例:無人駕駛。如果AI無人駕駛導致事故之后如何認定責任?過去傳統侵權法規則的原則總要找到一個主體,現在看主體,是汽車制造者,程序設計者?責任如何分配?這些都是個問題。林維教授認為,科技法學在技術的飛速發展背景下,還沒有隨科技發展一起蓬勃壯大。
林維教授通過一些案例提出問題,探討了以人工智能發展為代表的科技背景下,法學領域的一些新的研討方向。他以快播案判例討論了技術的中立問題,以深圳南山法院谷米訴元光以爬蟲技術抓取數據案判例討論了刑法第285條非法獲取計算機信息系統數據罪,說徐老師在技術研討中有一句話令人印象深刻:“數據爬蟲抓取數據的時候還是要遵紀守法。”由此林維教授引出了數據權屬,數據的利益在法律中如何定義的熱門法學話題。現有的判例是在不完美的法律框架中得到的一個最好的解決方案,相關立法還是不清晰不完美。微博屬于新浪的數據還是用戶的數據還是幾家共有?現在還沒有討論清楚。互聯網的泛在化導致了管轄的泛在化。涉及到的大批數據公司可能涉案,這個問題會嚴重影響整個數據產業的發展。特別需要在法律上有一個清晰說明,否則很多從事大數據的人都不敢涉足該領域,不僅僅是民事,可能構成刑事問題。
最后,林維教授希望大家繼續關注“人工智能”工作坊,關注社科大互聯網法學研究。
林維教授主題發言
參加首次“人工智能”工作坊研討的人員包括各層各類學生和部分專職教師及研究人員,首次直播參與者峰值達到149人。截止目前,工作坊報名總人數達到324人,以我校學生為主,其中本科生112人,碩士研究生124人,博士研究生58人。
本次計算機教研部的“人工智能”工作坊是我校“線上工作坊”形式的初次嘗試,下一期將邀請中國科學院國家空間科學中心的王特副研究員帶來“區塊鏈技術”的主題。
4月3日,不見不散!
計算機教研部供稿




